
一、传统数据中心概述
1、传统数据中心架构
传统网络架构通常是指基于分层网络设计的一种网络架构,旨在建立高效、可靠、可扩展的计算机网络系统。分层网络设计是Cisco在2002年提出的一种设计思想,分层网络设计统治了数以万计的局域网络。分层网络设计旨在通过划分网络层次,使得每个层次承担和管理指定的功能,实现类似协议设计的效果。通常传统网络架构分为接入层、汇聚层/分布层、核心层,接入层用于服务器/终端接入;汇聚层用于核心和接入之间,担任L2和L3的边界以及扩展网络的功能;核心层则用于高速转发。
传统网络架构包括了数据中心内部网络架构和数据中心之间的网络架构(即DCI),以下是两种架构的定义:
数据中心内部网络架构:内部网络架构称为局域网架构/传统分层架构更加贴切,内网架构通常是指采用分层模型进行组建和设计的网络。分层架构层级分为接入层、汇聚层、核心层,因此也被称为三层架构。分层架构的特点:
分层设计:接入设计、安全设计、路由设计、地址规划都会被分开。
树型架构:整个架构从拓扑图上看来像一棵树,因此也被称为树型结构。受限于分层架构,接入交换机并不是无限扩展,接入交换机的数量是根据汇聚交换机下行接口数量而决定的,这使得接入交换机数量远远多于汇聚交换机数量。汇聚交换机和核心交换机之间通常为了冗余仅仅会设置为两台互作备份,采用Full-Mesh的互联方式。汇聚交换机和核心交换机会被看作树干,而接入交换机会被看作树根,从下到上看似一种树型结构。
L2和L3故障域被隔开:汇聚层设备会通过配置将L2网络和L3网络隔离开,这也使得故障域被隔开。L2的故障仅限于接入交换机和汇聚交换机之间,而L3的故障仅限于汇聚交换机和核心交换机之间。
以南北向流量为主:应用被部署在同一台裸金属服务器中,业务被有部分被分离,东西向流量较少。无论是东西向流量还是南北向流量都需要经过汇聚交换机转发,这使得汇聚交换机性能和带宽需要被关注。
二层扩展性受限:当汇聚交换机下行接口被占满后,该网络则无法进行更大的扩展(不建议Trunk打通两个Pod之间的汇聚交换机)。
集中式网关:不同子网之间的通信通常需要经过默认网关,而分层网络设计要求冗余网关(实现高可用)。网络中的所有网关都会被集中部署在汇聚层交换机上,以实现不同子网的通信。
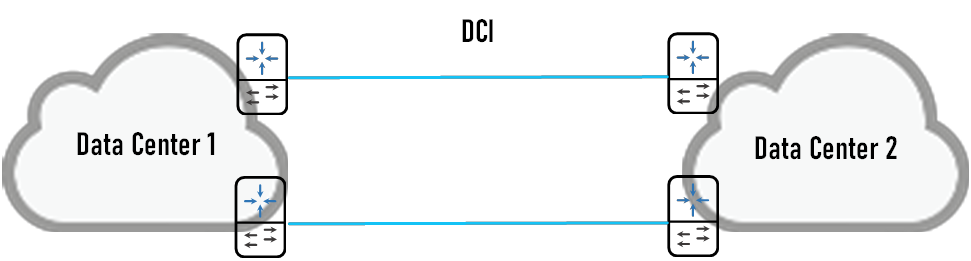
数据中心之间的网络架构:DCI是指通过数据中心互联技术将多地多机房网络互联互通,实现主备或双活数据中心的需求。
2、传统数据中心问题
随着虚拟化技术的发展,越来越多的应用已经部署在虚拟化之上。虚拟化技术带来的革新也是前所未有的,从上世纪90年代的计算虚拟化,扩展到现在的存储虚拟化和网络虚拟化,虚拟化技术极大的减少了运行大量工作负载所需的数据中心基础架构,将物理硬件资源的利用率提升到了一个新的高度(资本主义世界中的压榨到了极致)。根据2020年IDC白皮书《通过低碳数字化转型实现更敏捷和可持续的业务》估计,自2003年以来VMware的虚拟化技术在全球范围内帮助客户减少部署了1.42亿台裸金属服务器,相当于减少了24亿兆瓦能源,少排放了12亿吨温室气体。
虚拟化是云计算的底座技术。虚拟化为云计算提供了多种特性,包括资源隔离、多租户、弹性分配、快速部署和管理。业务和系统根据虚拟化技术的应用情况对自身架构进行重塑,一套完整应用的功能或者说是组件被切割,这些组件被分配到了不同的虚拟机中,这些虚拟机可能分布在不同的宿主机上,组件之间的流量传输从裸金属内部传输到需要依赖网络传输。虚拟化厂商例如VMware为了避免虚拟机发生故障导致业务宕机,带来了虚拟化高可用方案,包括虚拟机热迁移(vMotion)、虚拟机同步复制(FT)、存储热迁移(Storage vMotion)、虚拟机高可用(HA)、动态资源分配(DRS)等,高可用方案降低了业务故障发生的概率,但是部分特性需要依赖网络传输数据。因此总结虚拟化给网络所带来的挑战就是:
业务分布式化/解耦化给网络所带来的影响就是东西向流量剧增以及次优路径;
硬件资源池化所带来的虚拟机数量剧增;
虚拟化架构高可用方案依赖网络传输;
云计算多租户依赖更多的网络分段。
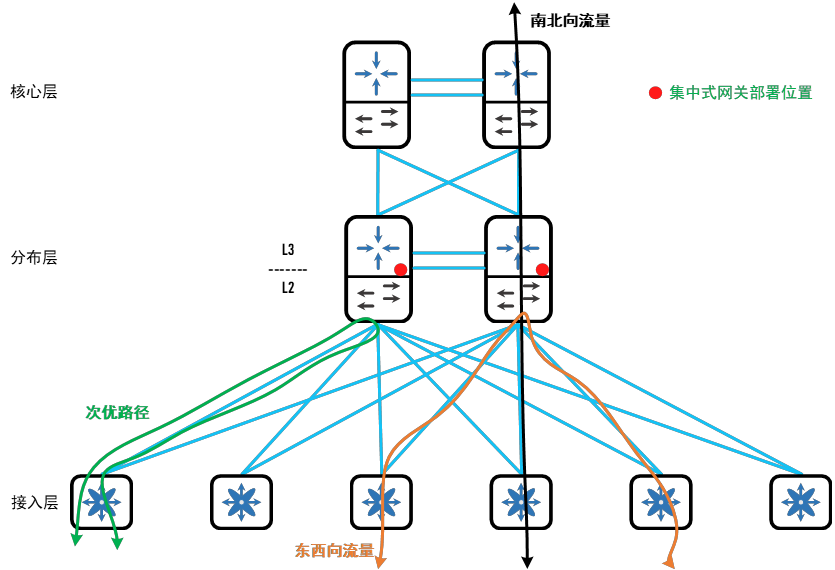
业务分布式化/解耦化给网络所带来的影响就是东西向流量剧增以及次优路径。网站高可用架构通常分为应用层、服务层和数据层。应用层负责具体业务处理逻辑,服务层负责提供功能服务,数据层则提供数据的存储和访问。互联网发展之初,应用层、服务器和数据层都被部署在同一台裸金属上。随着互联网经济的迅猛发展,为了提供更可靠的服务,业务部门开始将架构解耦,将应用层、服务层和数据层分别部署在不同的裸金属上,但由于硬件成本太高,引进虚拟化技术,这些组件就被部署在了不同的虚拟机上。为了防止单个组件发生故障以及单个组件处理性能底下,业务部门将单个组件扩展成了多个、多套,后来为了防止整个数据中心发生故障,建设灾备数据中心,部署了同样一套的业务。通常处理一条南北向访问数据,组件之间就需要进行多次通信,这就导致数据中心内部和数据中心之间东西向流量剧增。
硬件资源池化所带来的虚拟机数量剧增。传统网络场景中,一台ToR交换机的某个接口只能够学习到一台裸金属服务器的MAC;而在裸金属虚拟化的场景下,一台ToR交换机的某个接口可以学习到大概20~100个虚机的MAC。那么根据测算ToR交换机的容量从至少48个MAC上升到至少960个,这还不包括从其他桥接的交换机过来的MAC。CAM表项一旦溢出,则会导致交换机对后续接收的所有数据帧进行全端口泛洪,这会引发一些安全问题和不必要的资源消耗,这种行为会一直持续到CAM表项老化。
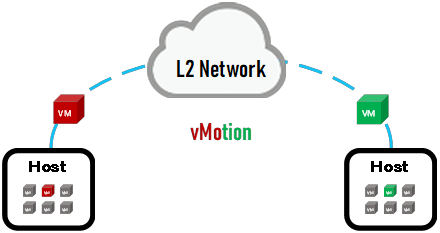
虚拟化架构高可用方案依赖网络传输。典型的例如虚拟机热迁移(vMotion)需要依赖网络传输,虚拟机热迁移通常发生在同一个二层网络域下。传统数据中心网络架构中,二层网络域通常位于接入和汇聚之间。接入交换机的服务器接入能力受到接入交换机的下行接口限制,通过汇聚交换机和接入交换机互联得以扩展二层域,但是最终服务器接入能力并不是无限扩展的,而是根据汇聚交换机的下行接口限制。以Cisco Nexus 9504作为汇聚交换机为例,满插4块N9K-X9536PQ(32 * 40Gbps),即能够容纳128台N93180/N93108接入交换机互联,能够容纳6144台裸金属服务器接入,虚机的数量122880。也就是从理论上来说采用两台Nexus 9504所构建的二层网络最多能够容纳6144台裸金属,通常一组交换机所构建的二层网络最大容纳裸金属数量的域叫做Pod。此时如果仍然需要扩展裸金属数量就需要构建一套新的Pod,将Pod之间的汇聚交换机互联以达到扩容的效果,但是这种二层扩展会带来很多问题,或者将Pod之间采用三层路由隔开,但是这也会导致一些新的问题出现。在讨论二层网络扩展问题之前,先对二层网络的问题进行剖析。传统数据中心二层网络通过部署生成树协议以避免出现广播风暴,由于Ethernet中没有TTL这样的字段,因此理论上数据帧可以无休止的被交换机转发(环形连接拓扑),短短数秒就会出现大量的数据帧,这种情况会造成二层网络转发效率下降,严重的会导致交换机故障,业务宕机。生成树协议通过控制层面的手段将二层网络构建成一个无环的拓扑,但是由于生成树协议属于早期网络协议设计,因此存在很多局限性:
收敛速度慢:二层网络出现问题就会触发生成树协议重新计算,而根桥出现问题时,这种影响面将被扩大。网络中会出现大量的TCN BPDU,交换机MAC地址表项迅速老化并重新学习。尽管可以通过部署生成树优化特性,但是在链路速率为10~100Gbps的网络即使亚秒级的收敛也会导致严重丢包,更何况生成树协议的收敛时间至少是秒级,数据中心网络对此无法容忍。
链路带宽低:生成树协议从控制层面生成了一个无环的二层网络,这使得部分上行链路会被阻塞,链路带宽无法被有效利用,数据中心所属组织无法容忍这部分无法被利用的成本。
次优路径转发:生成树协议的好搭档就是首跳冗余协议,配合集中式网关的部署。集中式网关的转发特权和生成树根桥通常位于汇聚交换机,因此南北向流量和东西向流量都需要经过汇聚交换机路由,即使接入交换机之间存在更短的路径。
缺乏等价路径:部署了生成树协议的二层网络无法实现等价路径,因为始终有上行链路会被阻塞。
双归接入问题:传统Port-Channel不支持服务器跨机框配置链路汇聚。
MCEC(Multichassis EtherChannel,多机框链路汇聚)技术例如vPC、VSS、M-Lag支持服务器跨机框配置链路汇聚。以vPC举例,它能够将两台交换机对外逻辑上呈现出一台交换机的形式,也就是说对服务器来说,部署了vPC技术的两台接入交换机就是一台,服务器认为LACP对端的节点就是一台交换机,服务器的流量通过LACP均衡的被vPC交换机转发。接入交换机仍然可以同汇聚交换机组建vPC,这种组网方式也叫背靠背vPC。网关会被集中部署在汇聚交换机,配置了vPC的汇聚交换机仍然会部署负载网关技术(例如HSRP、VRRP),传统场景下只有Active的网关会继承VIP并进行ARP响应和转发,负载网关技术在vPC的场景下被优化了,两台vPC交换机都能够转发数据。vPC的防环特性有别于生成树协议,其采用数据层面防环,因此不存在链路阻塞问题。尽管vPC解决了传统生成树协议的很多问题,诸如收敛速度慢、链路带宽低,但是其只能允许两台交换机组建vPC,人们对通用多路径的需求越来越强烈。前面提到多个Pod之间可能会部署相同的二层域,以方便虚拟机高可用方案的实现以及为云计算技术提供硬件资源池化的能力,因此二层网络的扩展需求被摆上台面。二层网络的扩展方案通常有两种,分别是Pod之间二层互联、Pod之间三层互联。现在来谈论下两种扩展的问题:
1)Pod之间二层互联:首先第一点就是受限于通用多路径的需求,这点儿二层互联仍然是无法实现。第二点就是二层网络服务器越来越多,会导致网络中的所有交换机都学习到所有服务器的MAC,这点无法通过不断提高硬件容量来实现。第三点就是不断扩展二层互联,会导致二层故障域越来越大,BUM流量也会消耗本就不该消耗的硬件计算能力。
2)Pod之间三层互联:Pod之间如果采用三层互联,这就有一个问题,两个Pod内的二层如何打通?因为三层网络隔离了二层网络域。通过隧道的方式传递二层数据帧是一种很好的方式。Pod之间的边缘设备运行路由协议以及隧道封装协议,Pod之间的边缘设备通过隧道相互交换二层数据帧。Pod之间三层互联也是目前最常用的方式。
云计算多租户依赖更多的网络分段。云计算涉及为多租户环境按需弹性调配资源以及网络隔离,云服务提供商通过同一套物理基础设施为多个客户提供弹性服务,租户可以通过L2或L3网络隔离流量。传统的VLAN技术通过定义12bits的VLAN ID用于识别和隔离,在数据中心中每个租户可能会使用至少一个,甚至可能多个VLAN ID,因此4096个二层网络分段已经捉襟见肘,但是二层即插即用的特性仍然需要保留下来。通过关联Pod之间的三层互联以及扩展二层网络分段,覆盖层技术被提出。
二、新一代数据中心
根据上一章节所总结的四点,传统数据中心网络对此毫无招架之力,新一代数据中心网络亟待解决这些问题。新一代数据中心网络通过覆盖层技术解决虚拟化架构高可用方案依赖网络传输以及云计算多租户依赖更多的网络分段的问题;通过脊叶网络架构以及分布式网关解决业务分布式化/解耦化给网络所带来东西向流量剧增、次优路径问题以及硬件资源池化所带来的虚拟机数量剧增的问题。
1、Overlay&Underlay
覆盖层技术也叫Overlay,覆盖层技术是一种叠加网络/逻辑网络/虚拟网络/抽象网络,覆盖层是指在物理网络架构基础上建立起一条静态或动态的隧道技术。常见的覆盖层技术包括GRE、IPsec、MPLS、6in4、L2TPv3,覆盖层技术通常用于安全、简化路由查找以及底层网络承载新型流量等场景。覆盖层技术的特点就是边缘设备再原始数据帧的基础上为其添加覆盖层协议首部以及新的外层包头和外层帧头,中间设备只需要利用外层包头和外层帧头进行传输,无需了解覆盖层协议首部。目标边缘设备会对其进行解封装,根据覆盖层协议首部进行数据的二次处理后转发。
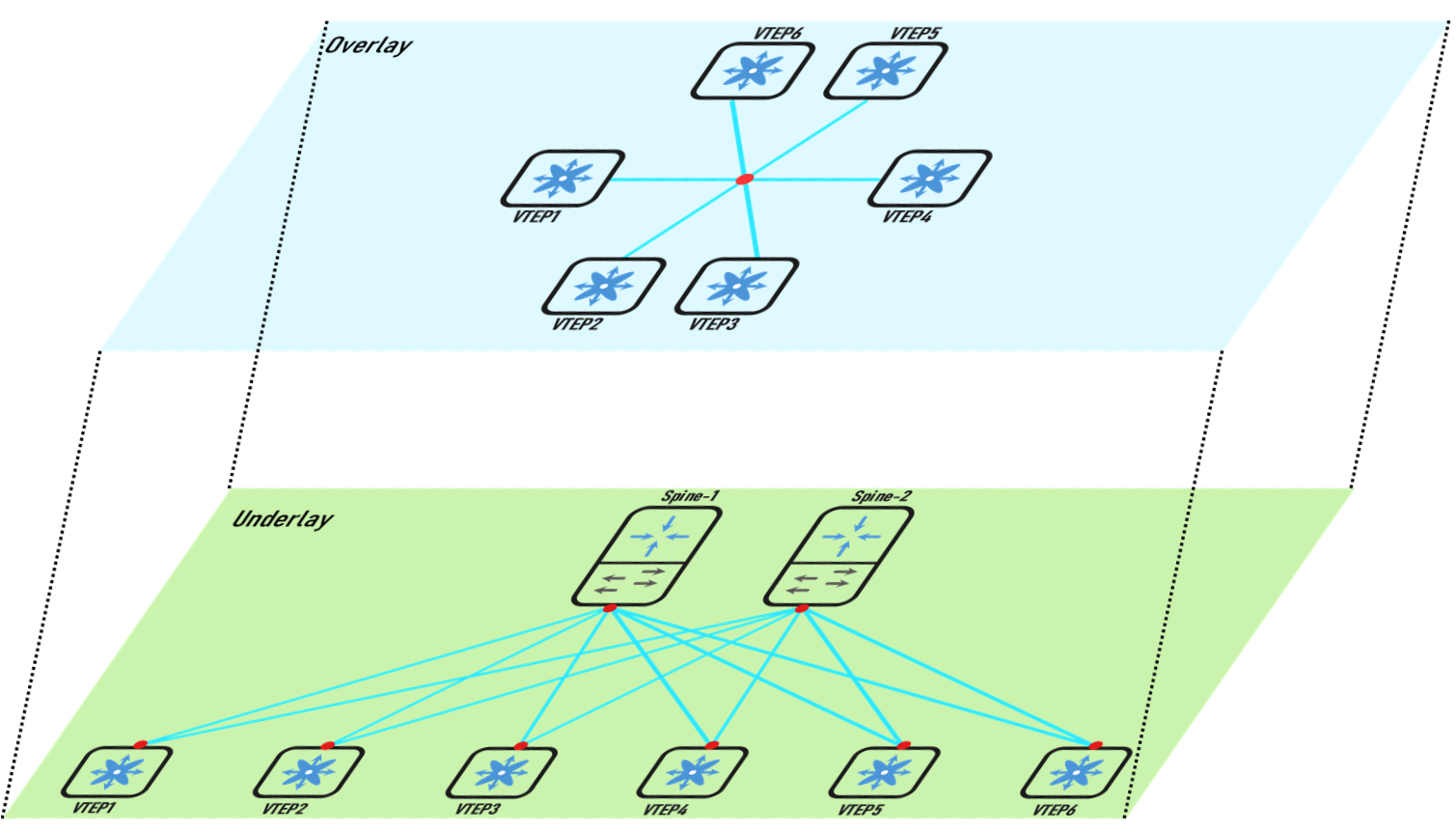
Overlay之下的物理网络架构就是Underlay。Underlay表示底层网络,底层网络负责基础网络设施之间的基本网络互通。基于Underlay可以构建多个Overlay,多个Overlay共享同一套Underlay基础设施,Overlay之间默认相互隔离,可以通过Gateway技术将其打通。Underlay网络可以采用L2也可以采用L3,L3通常采用路由协议打通,例如OSPF、IS-IS、EIGRP、iBGP(IPv4 Address Family)等。
Overlay基于Underlay构建,用于将二层扩展至多个数据中心,提供虚拟化灵活性和迁移性的必要基础环境。正确理解两者的关系,Underlay是Overlay实现的基础,Underlay网络只有一个,在该网络中的节点互联互通。Overlay通过端到端应用处理构建逻辑网络拓扑,Overlay设备之间建立数据转发隧道。总结下两种网络的优势:
Underlay优势:
可路由网络/IP网络:支持多种路由协议,例如OSPF、IS-IS、EIGRP、iBGP(IPv4 Address Family)等,甚至你可以玩的更花。
弹性拓扑/冗余路径:支持等价多路径。
组播优先:支持组播路由协议。
单播复制:IP网络所带来的优势。(不建议使用,单播复制会加重始发VTEP硬件资源)
Overlay优势:
多租户网络隔离。
二层扩展。
继承所有Underlay优势。
2、脊叶网络架构
随着信息化发展,数据中心承载的业务越来越多,重要性也不言而喻。为了应对大规模访问以及提高资源利用率,虚拟化、分布式存储、分布式计算被广泛应用,东西向流量大幅增加,这使得原本以南北向流量为主的层次化架构难以为继。借助交换机矩阵交换架构的思路,工程师将CLOS架构应用于网络组网中。CLOS架构应用于网络架构中后,换了一种名称叫脊叶网络架构(即Spine-Leaf Arch)。脊叶网络架构无论是南北向流量还是东西向流量都是适用的,服务器到服务器的东西向路径无论经过哪条负载链路,经过的设备跳数都是3(即本端VTEP、任意Spine、对端VTEP三跳)。
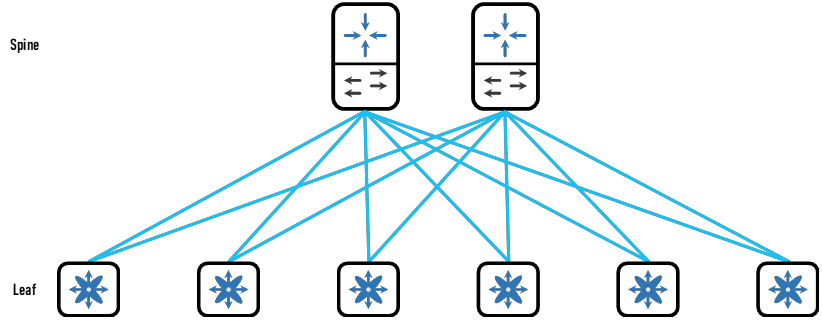
脊叶架构由Spine和Leaf构成,Spine用于IP网络高速转发,Leaf则用于提供服务器接入、L4~7层服务接入、外部网络接入的功能。在脊叶架构中,每台Leaf和所有Spine互联,Spine之间不进行任何连接,Leaf之间也不进行任何连接,Spine和Leaf互联的链路看似网状,因此也叫矩阵(IP Fabric)。用于提供服务器接入的Leaf叫做Server Leaf,用于L4~7层服务接入的Leaf叫做Service Leaf,用于外部网络接入的Leaf叫做Border Leaf。
Server Leaf:用于提供服务器双归接入&分布式网关,此处可以选择采用互联组建vPC。
Service Leaf:用于提供L4~7层服务的接入,例如防火墙、负载均衡、SSL证书卸载设备、加密机等。
Border Leaf:用于提供外部网络的接入。
Spine和Leaf之间采用IGP协议构建Underlay,在Underlay的基础上构建Overlay网络,实现更高层次的功能,例如二层扩展。
脊叶架构特点分析:
高速转发:指的主要是Spine。Spine只承担IP网络功能,因此较少的功能、较短的转发路径、更多的负载链路使得Fabric的转发效率更高。
路径优化:相比较传统网络,VM端到端数据转发不超过三台Fabric设备。
弹性扩容:灵活调整Spine的数量,都不会影响整体网络的运行。无论是新增还是减少Spine的数量,都不会影响现有的Leaf转发。减少Spine数量时可能需要关注Leaf其他上行链路的带宽利用率,增加Spine数量时需要关注Leaf可用的上行链路接口数量。
可靠组网:任一Spine或Leaf故障都不会对矩阵中的流量转发产生影响。一方面L2部署vPC进行负载分担,即使一根线路断开,另外一根线路仍然可以正常工作,另一方面L3部署ECMP,上行链路至少2根,断开一根线路也不会影响流量转发。
流量负载分担:
L3 ECMP:得益于IP网络和Fabric互联特点所继承的ECMP,流量进入Leaf后会根据等价路由被负载转发。上行冗余负载链路数量根据Spine的数量而定。Spine数目越多,链路负载越低,冗余率越高。
L2 vPC:Leaf提供双规接入,基于LACP负载,为服务器提供更高的带宽和冗余性。
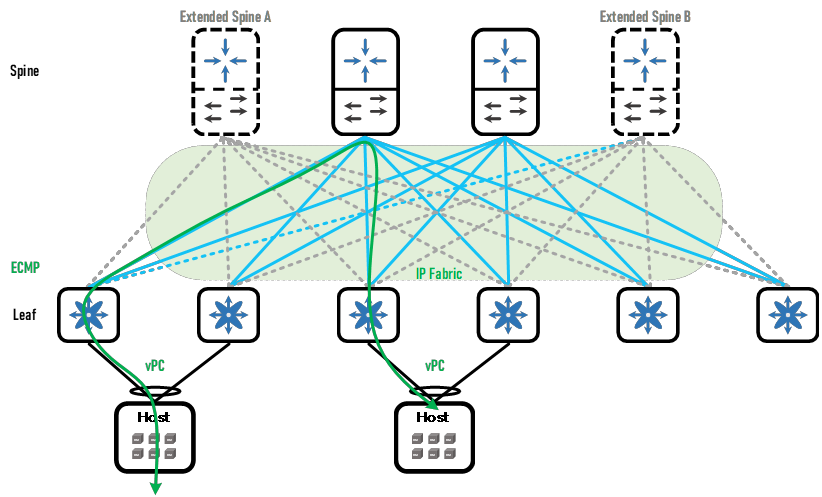
3、分布式网关

传统网络架构中常常会采用集中式网关的部署方式。在脊叶架构中也采用集中式网关是否可行?可行,但不是最优。脊叶架构通常会在Border Leaf上部署集中式网关,所有Server Leaf会将不同子网的流量发往Border Leaf,通过Border Leaf路由后再转发给目标Server Leaf,其流量路径就像少女的发卡一样,因此也被称为“发卡流量(Hair-pin)”。发卡流量的转发路径仍然是次优路径,这点是集中式网关的特点,因此无论是在传统网络架构中还是脊叶网络架构中,只要部署集中式网关就会出现次优路径。次优路径会导致虚机之间的通信产生不必要的延迟和负载。部署集中式网关的设备需要较高的性能,因为需要更大的MAC和ARP表项容量以及转发性能,但是随着VM的不断部署,仍然可能会出现性能瓶颈。为了避免集中式网关设备故障通常会部署多台或多集群,这大大增加了购买和维护成本。总结集中式网关的缺点:
次优路径
性能瓶颈
高额成本
更高延迟
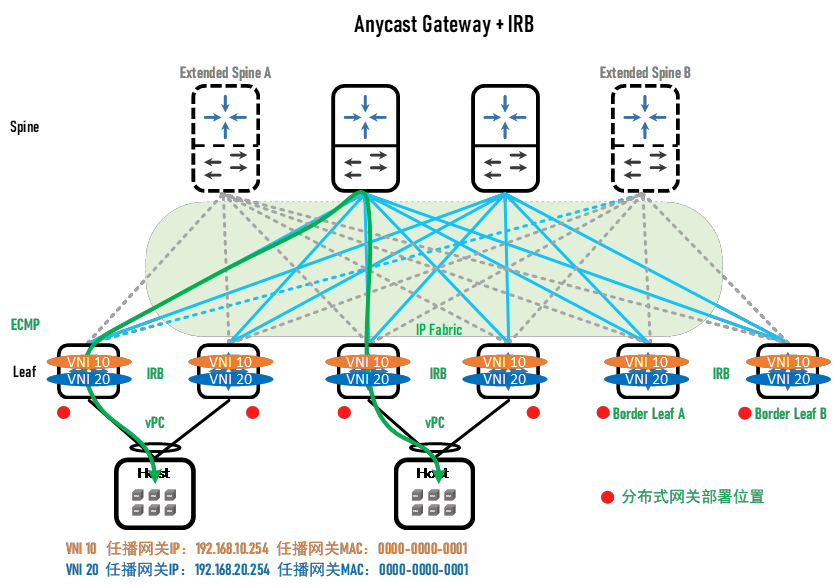
能否将L2/L3的分界点部署在Leaf,这样的话上述集中式网关部署的四个缺点都能避免。将网关部署分布在矩阵的Leaf/ToR交换机上,这种部署方式叫做分布式网关部署。由于网关分布在各个Leaf上,不同子网互访流量将被各自的Leaf首先处理,这使得“下一跳即网关”的理念得以实现,无需穿越二层域来访问默认网关了。每台Leaf上的分布式子网网关都处于活跃状态,同一个子网网关可以位于多台Leaf上,因此无需再使用FHRP。为了实现双归接入,仍然需要部署vPC以及优化型FHRP,以提供服务器或虚机的负载接入和下一跳即网关。从vMotion的角度来看,虚机的ARP表项中存在网关的IP-MAC的对应关系,如果虚机从一台Leaf迁移到另外一台Leaf上,MAC发生变化则会导致流量黑洞,为了避免这种情况,分布式网关的MAC应当是共享的,这种MAC也叫AGM(Anycast Gateway MAC,任播网关MAC)。所有子网都会使用这个相同的MAC,但是子网之间的IP地址则采用专门的IP。总结所有的Leaf上的所有子网都共享同一个AGM,独享不同的IP,以实现虚机迁移。L2/L3的分界点被部署在了Leaf上,因此网络故障域变小了,简化了配置,路由转发也得以优化(分布式网关配合IRB解决了无论是南北向还是东西向的发卡流量问题)。
评论